intro
One problem with online learning overtime is distributional shift. If tomorrow’s data looks different from today’s data, then today’s model will need to learn to adapt to tomorrow’s data distribution. Some approaches in meta-learning research (e.g. finetuning, freezing weights, MAML, etc.) address this problem. This post will take a more hamfisted approach and explicitly free model parameters to accomodate distributional shift.
The Python (tensorflow) code is available on GitHub.
idea
The idea is a variant on finetuning:
- Use dropout to ensure robustness when some nodes in the net are unavailable.
- When new data is introduced, reset some of the weights in the hidden layers. Training on the new data will result in these reset connections learning the differences between the old data generating distribution and the new one.
code
network architecture
for i, (num_units, activation_func, prob_keep) in iterator:
with tf.variable_scope('hidden%i' % i):
layer = tf.layers.dense(layer, num_units)
layer = tf.layers.dropout(layer, prob_keep)
with tf.variable_scope('output'):
output = tf.layers.dense(layer, num_out, name='output')
reset operations
reset_ops = []
for i, prob in enumerate(self.parameters.prob_keep_perm):
with tf.variable_scope('hidden%i' % i, reuse=True):
weights = tf.get_variable('dense/kernel')
mask_reset = tf.cast(tf.random_uniform(weights.shape) < prob, weights.dtype)
reset_ops.append(tf.assign(weights, weights * mask_reset))
results
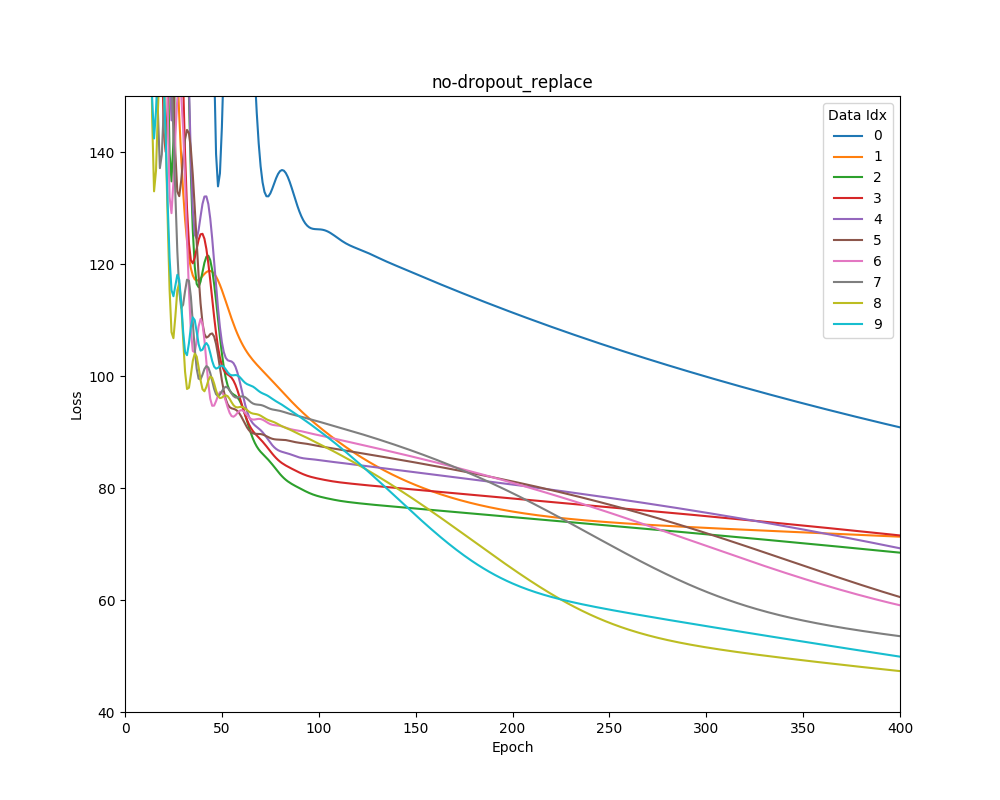
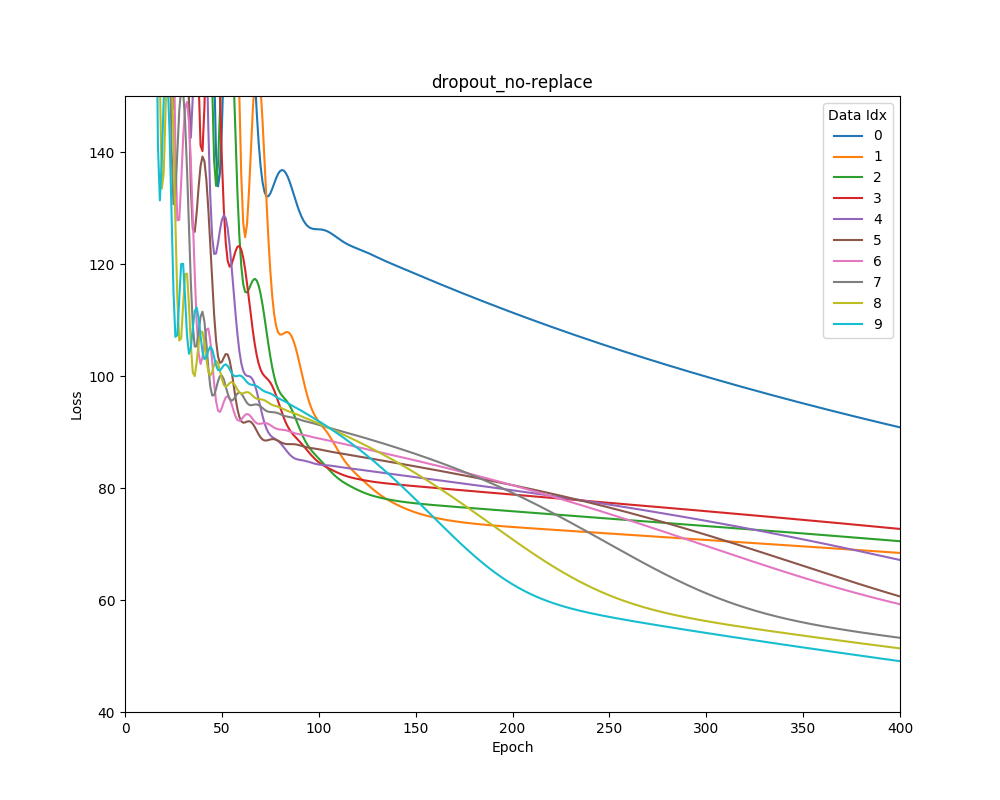
Graphed are mean square error losses on scikit learn’s Boston house-price dataset as the dataset is shifted over time.
No Dropout No Weight Replacement
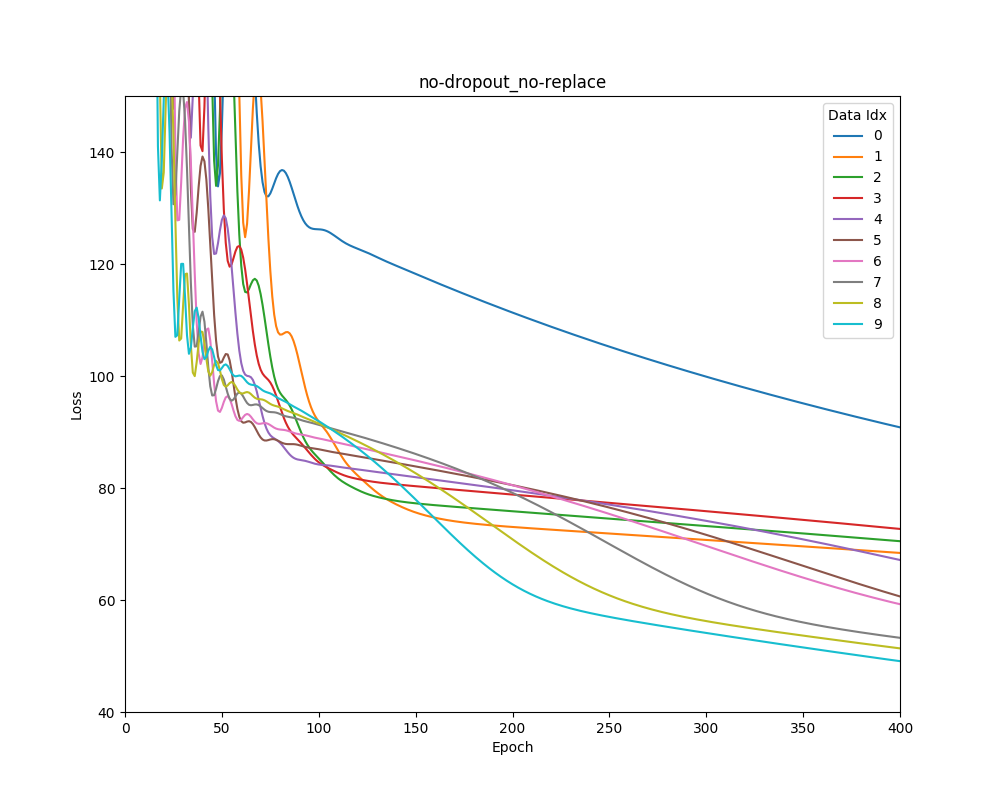
No Dropout Weight Replacement
Dropout No Weight Replacement
Dropout Weight Replacement
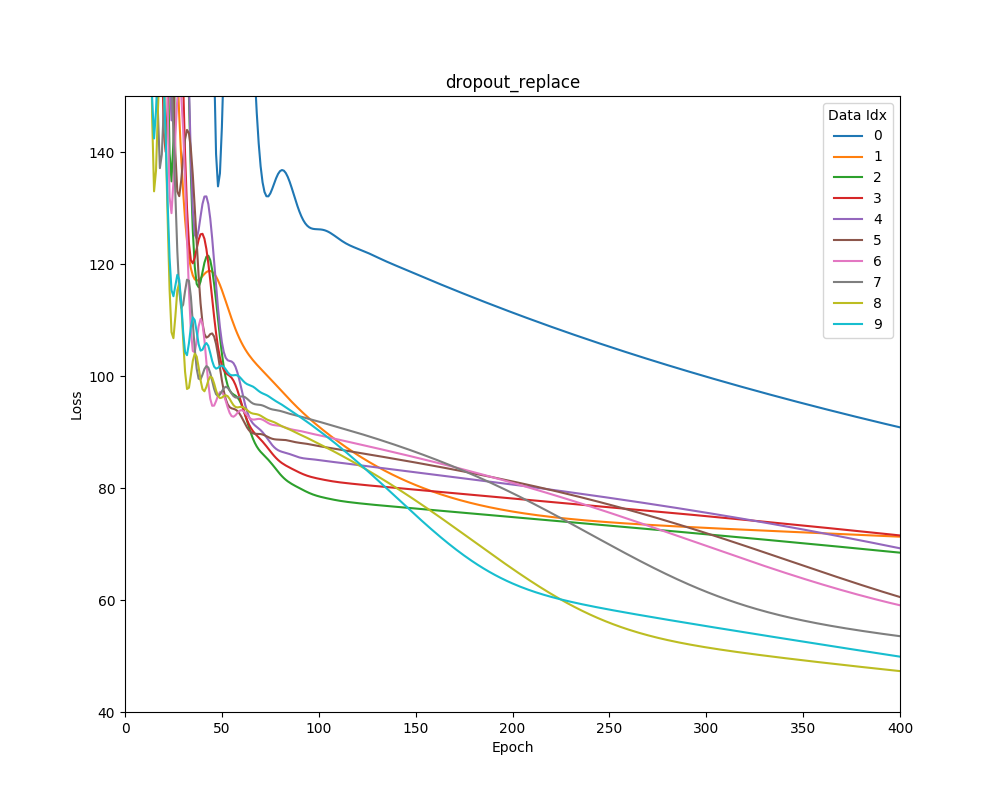
Dropout with weight replacement results in lower training error soon after new data is introduced.